Introduction
As mentioned in the previous blog article “Microservices with AWS Serverless”, AWS Serverless removes the need to maintain infrastructure, while reducing overhead and allowing more time for development, which eventually leads to a faster time-to-market. When a microservice’s scope fits the scope of an AWS Lambda function, it can be effectively built, deployed and monitored in addition with services like Amazon API Gateway, Amazon DynamoDB, and AWS CloudWatch.
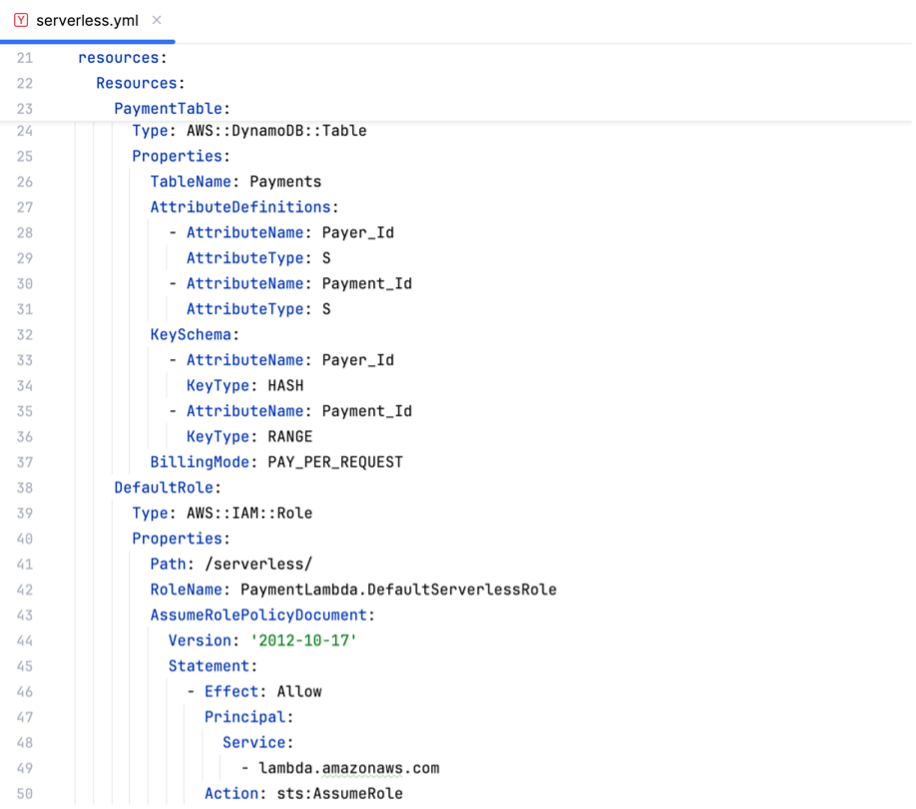
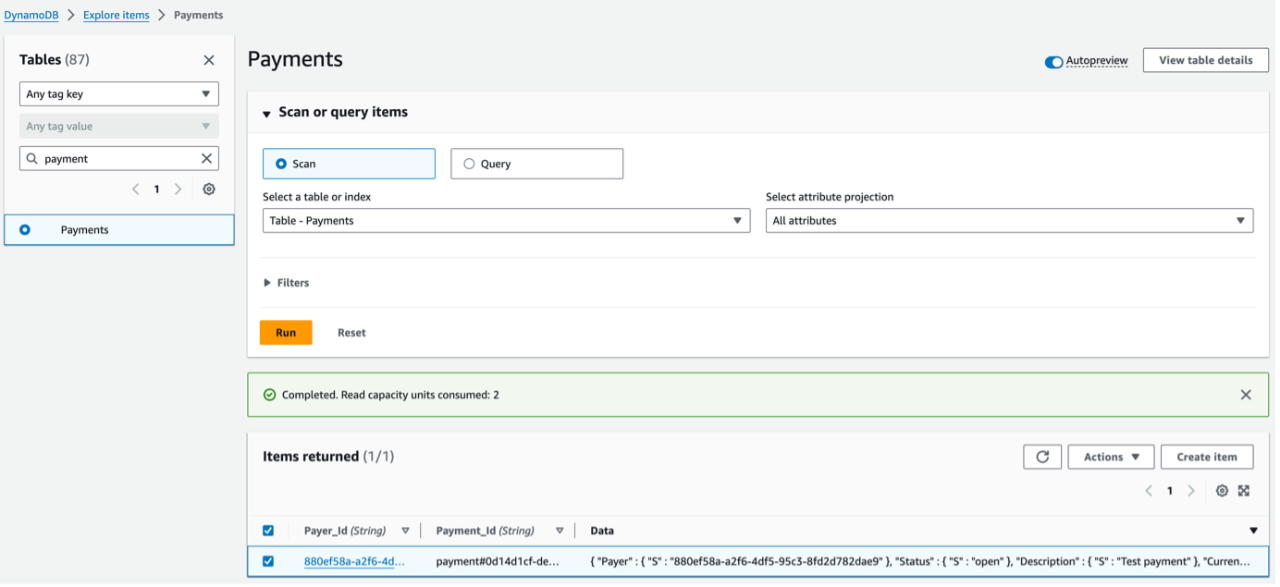
Thus, this blog post focuses on showing a concrete implementation example of a simple microservice application, written in Golang and leveraging AWS Lambda amongst some other AWS Serverless services.