Einleitung
Im vorangegangenen Blog-Artikel „Microservices mit AWS Serverless“ hatte ich bereits erwähnt, dass mit AWS Serverless die Notwendigkeit, Infrastruktur zu warten, entfällt. Das reduziert den Overhead und es bleibt mehr Zeit für die Entwicklung, was letztlich zu einer schnelleren Time-to-Market führt. Wenn der Scope eines Microservices in den Scope einer AWS Lambda-Funktion passt, kann er zusätzlich mit Services wie Amazon API Gateway, Amazon DynamoDB und AWS CloudWatch effektiv entwickelt und überwacht werden.
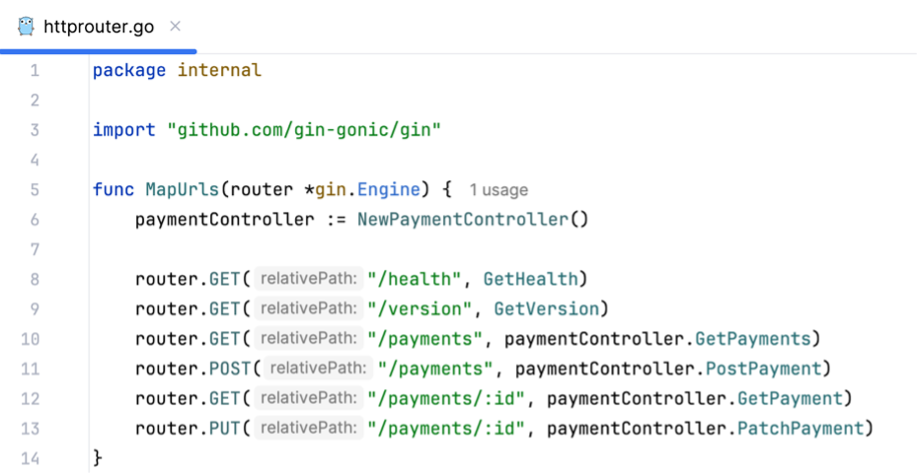
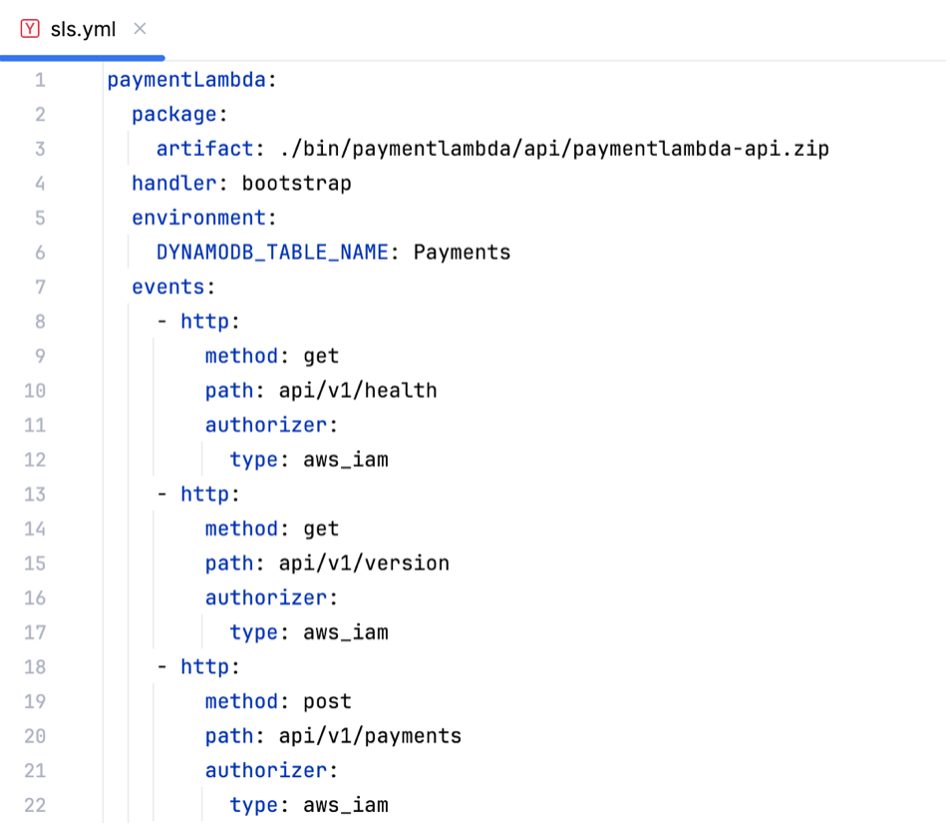
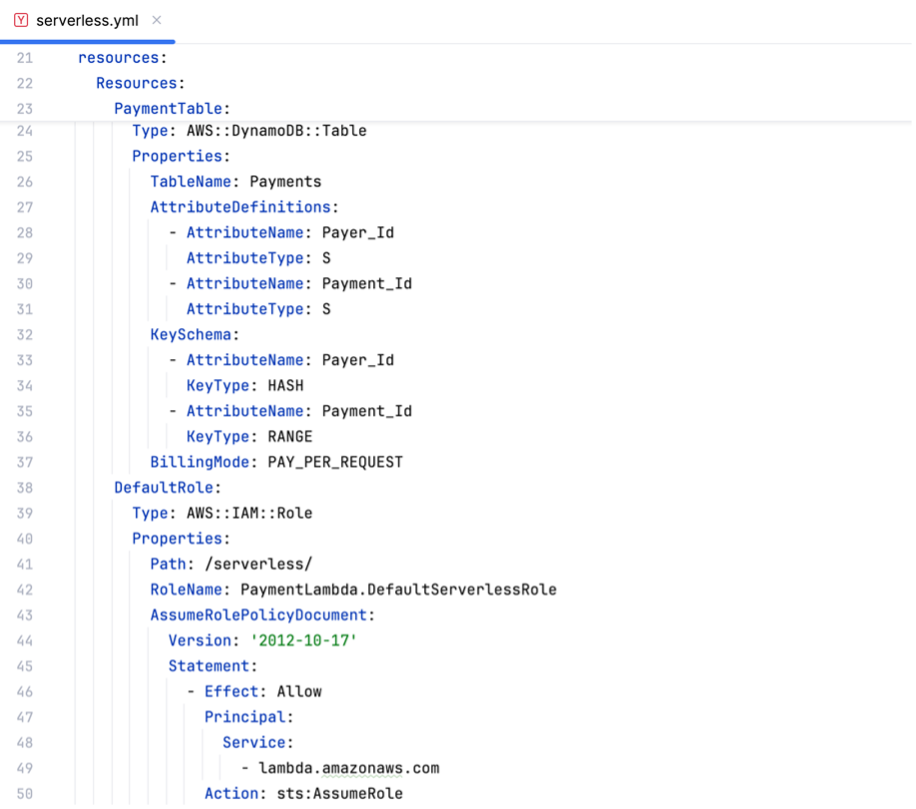
Dieser Blog-Beitrag beschäftigt sich mit der Umsetzung eines konkreten Beispiels für eine einfache Microservice-Anwendung, die in Golang geschrieben wurde und AWS Lambda sowie einige andere AWS Serverless-Services verwendet.